zhuanzi: https://blog.csdn.net/qq_33689414/article/details/78973267
pandas之groupby分组与pivot_table透视表
在使用pandas进行数据分析时,避免不了使用groupby来对数据进行分组运算。
groupby的参数
groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
-
by:mapping, function, str, or iterable。
用于确定groupby的组。如果by是一个函数,那么会调用对象索引的每个值。如果传递了一个dict或Series,则将使用Series或dict的值来确定组。一个str或者一个strs列表可以通过自己的列传递给group。
-
axis:轴,int值,默认为0
-
level:如果axis是一个MultiIndex(分层),则按特定的级别分组。int值,默认为None
-
as_index:对于聚合输出,返回带有组标签的对象作为索引。
as_index=False实际上是“SQL风格”分组输出,boolean值,默认为True。 -
sort:排序。关闭此功能以获得更好的性能。boolean值,默认True。
-
group_keys:当调用apply时,添加group key来索引来识别片断。boolean值,默认True。
-
squeeze:尽可能减少返回类型的维度,否则返回一致的类型。boolean值,默认False。
groupby的聚合函数
groupby的聚合函数有:
| 函数名 | 说明 |
|---|---|
| count | 分组中非NA值的数量 |
| sum | 非NA值的和 |
| mean | 非NA值的平均值 |
| median | 非NA值的算术中位数 |
| std、var | 无偏(分母为n-1)标准差和方差 |
| min、max | 非NA值的最小值和最大值 |
| prod | 非NA值的积 |
| first、last | 第一个或最后一个非NA值 |
groupby示例
groupby的测试数据:
- 读取groupby_test.csv文件中的数据,输处文件内容。
if __name__ == '__main__': data = pd.read_csv('groupby_test.csv') print(data[:10]) 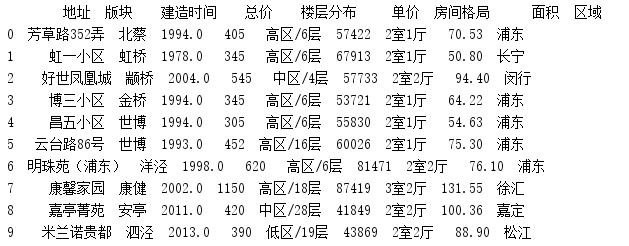
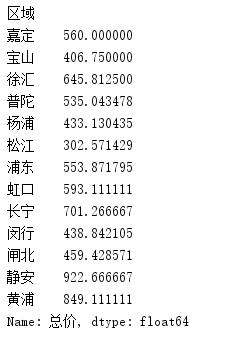
- groupby函数,对区域字段进行分组,对总价求平均值。
results = data.groupby(['区域'])['总价']print(results) # 输出:print(results.mean())
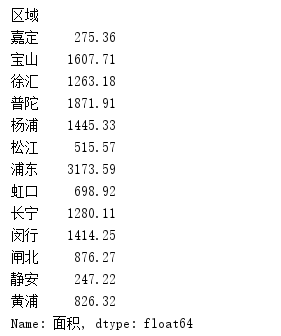
- groupby函数,对区域字段进行分组,对面积求和。
results = data.groupby(['区域'])['面积'].sum() print(results)
- groupby函数,对区域字段进行分组,对区域计算count。
results = data.groupby(data['区域'], sort=False)['区域'].count() print(results)

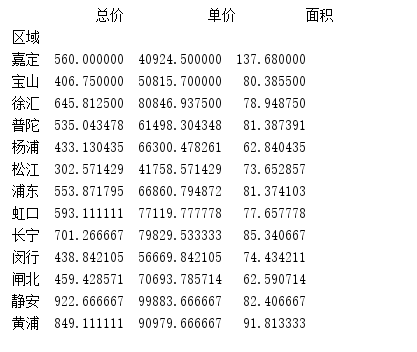
- groupby函数,对区域字段进行分组,求总价,单价,面积的平均值。
results = data.groupby(['区域'])['总价', '单价', '面积'].mean()print(results)
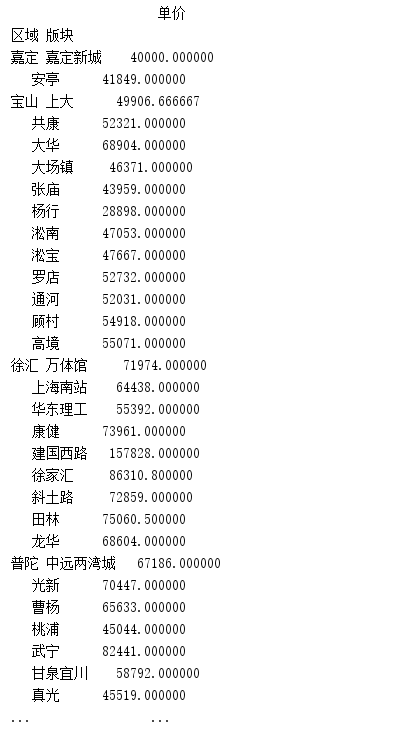
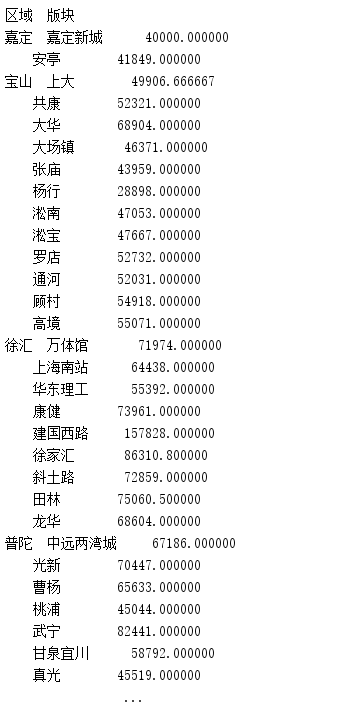
- groupby函数,对区域,版块2个字段进行分组,求单价的平均值。
results = data.groupby(['区域', '版块'])['单价'].mean()print(results)
pivot_table透视表
使用pivot_table透视表实现groupby的功能
results = pd.pivot_table(data, index=['区域', '版块'], values=['单价']) print(results)